基础巡检
为帮助企业客户降低人工巡检的成本,平台的基础巡检功能基于为企业客户执行人工巡检的经验设计。能够帮助企业客户实时了解平台上的所有业务资源的运行情况,及时感知异常,降低业务风险。
-
支持在线执行巡检任务,包括平台上所有集群、节点、容器组、证书资源的资源风险巡检以及常规资源的用量巡检,实时获取巡检进度;
-
巡检结束后,可视化展示巡检结果,包括资源风险、资源用量信息;
-
支持下载 PDF 或 Excel 格式的巡检报告;
-
为保障客户数据安全,仅允许具有相关访问权限的用户使用巡检功能。
操作权限说明
-
平台管理员:或具有平台管理相关权限的用户,可执行巡检任务、下载巡检报告、查看巡检资源详情;
-
平台审计人员:或具有平台审计相关权限的用户,可查看巡检结果、下载巡检报告、查看巡检资源详情。
执行巡检
-
在左侧导航栏中,单击 运维中心 > 巡检 > 基础巡检。
提示:巡检页面展示的巡检数据信息为最近一次巡检的结果。巡检过程中,可实时查看完成巡检的资源数据。
-
在基础巡检页面,支持以下操作:
-
执行巡检:单击页面右上角的 巡检 按钮,即可对平台进行巡检。
-
下载巡检报告:单击页面右上角的 下载报告 按钮,在弹出的对话框中选择报告格式(PDF 和 Excel)后单击下载,即可将相应格式的报告下载至本地。
-
PDF 格式巡检报告内容不包含资源风险详情页面数据;
-
Excel 格式巡检报告内容为巡检的全部数据;
-
支持同时下载两种格式报告。
-
-
巡检配置
| 巡检配置 | 描述 | ||
|---|---|---|---|
| 定时巡检 | 自动触发任务执行的定时规则,支持输入 Crontab 表达式。详细的设置方法可参考
如何设置定时触发规则?
。 提示:单击输入框,可展开平台预设的 触发规则模板, 选择适合的模板并简单修改后即可快速设置触发规则。 |
||
| 巡检记录保留 | 保留巡检记录的条数。 | ||
| 邮件通知 | 选择邮件通知联系人。 注意:通知联系人需配置邮箱。 |
||
| 巡检报告名称 | 平台内置的巡检通知模板将使用该名称通知联系人。 | ||
| 巡检配置项 | 在平台默认的证书、集群主机和容器组巡检项中,根据需求修改预警阀值或关闭巡检项。 |
巡检报告说明
最近一次巡检
在 最近一次巡检 信息区域,可查看最近一次巡检的相关信息:
-
巡检时间:最近一次巡检的开始时间和结束时间。
-
巡检资源总数:最近一次巡检总共巡检的资源(集群、节点、容器组、证书)总数。
-
风险:存在风险的资源个数。包括发生 故障 和 预警 的资源个数。
资源风险巡检
在 资源风险巡检 页面,可查看平台上 global 集群、自建集群、接入集群以及所有集群下节点、容器组、证书的风险信息总览。
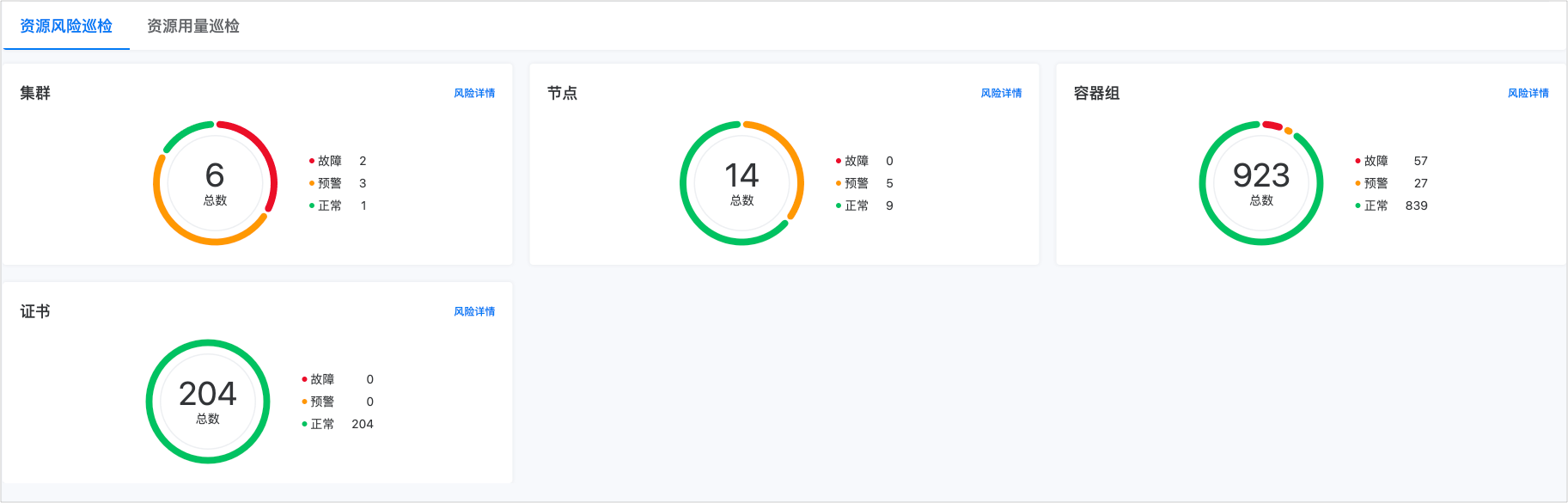
单击对应类型资源(集群、节点、容器组、证书)卡片上的 风险详情 按钮,即可进入对应类型资源的风险详情页面。在详情页面,可查看资源的最近一次巡检信息,以及存在故障和预警的资源列表。
-
单击资源名称,可跳转资源详情页面。
-
单击列表 名称 字段右侧的
 可展开故障、预警的判断条件和原因。
可展开故障、预警的判断条件和原因。
资源的风险状态(故障、预警)判断条件说明参见下表。
说明:用于判断每类资源故障、预警的条件包含多条,当资源的巡检数据匹配到判断条件中任一一条时,即作为一条风险数据。
| 资源类型 | 巡检范围 | 故障判断条件 | 预警判断条件 |
|---|---|---|---|
| 集群 | - global 集群 - 自建集群 - 接入集群 |
- 集群状态为 异常; - apiserver 连接异常 |
- 集群的 CPU 使用率大于 60%; - 集群的内存使用率大于 60%; - 集群的 ETCD 组件的任一容器组处于非 Running 状态; - 集群中任一主机处于非 Ready 状态; - 集群内任意 2 个节点的系统时间差超过 40S; - 集群的 CPU 请求率(实际请求值 / 总额 )大于 60%; - 集群的内存请求率(实际请求值 / 总额 )大于 80% ; - 集群未部署监控组件; - 集群的监控组件异常; - 集群中的 kube-controller-manager 组件的任一容器组处于非 Running 状态; - 集群中的 kube-scheduler 组件的任一容器组处于非 Running 状态; - 集群中的 kube-apiserver 组件的任一容器组处于非 Running 状态。 |
| 节点 | - 所有控制节点 - 所有计算节点 |
- 节点状态为 异常; - 节点上的 node-exporter 组件的容器组处于非 Running 状态; - 节点上的 kubelet 组件的容器组处于非 Running 状态。 |
- 节点的 CPU 使用率大于 60%; - 节点的内存使用率大于 60%; - 节点目录的磁盘空间使用率大于 60%; - 节点的系统负载大于 200% 且运行时间大于 15 分钟; - 过去 1 天内,至少发生过一次 NodeDeadlock(节点死锁)事件; - 过去 1 天内,至少发生过一次 NodeOOM(节点上内存溢出)事件; - 过去 1 天内,至少发生过一次 NodeTaskHung(节点上任务被挂起)事件; - 过去 1 天内,至少发生过一次 NodeCorruptDockerImage(节点上有损坏的 Docker 镜像)事件。 |
| 容器组 | 所有容器组 | - 容器组状态为 错误; - 容器组处于启动状态的时长超过 5 分钟。 |
- Pod 的 CPU 使用率大于 80%; - Pod 的内存使用率大于 80%; - Pod 在过去 5 分钟内的重启次数大于等于 1 次。 |
| 证书 | - Certmanager 证书 - Kubernetes 证书 |
证书状态为 过期。 | 证书的有效期小于 29 天。 |
资源用量巡检
单击 资源用量巡检 页签,进入 资源用量巡检 页面。
在 资源用量巡检 页面,可查看平台上 global 集群、接入集群、自建集群的 CPU、内存、磁盘总量、用量、使用率,以及平台上集群、节点、容器组、项目等资源的个数。
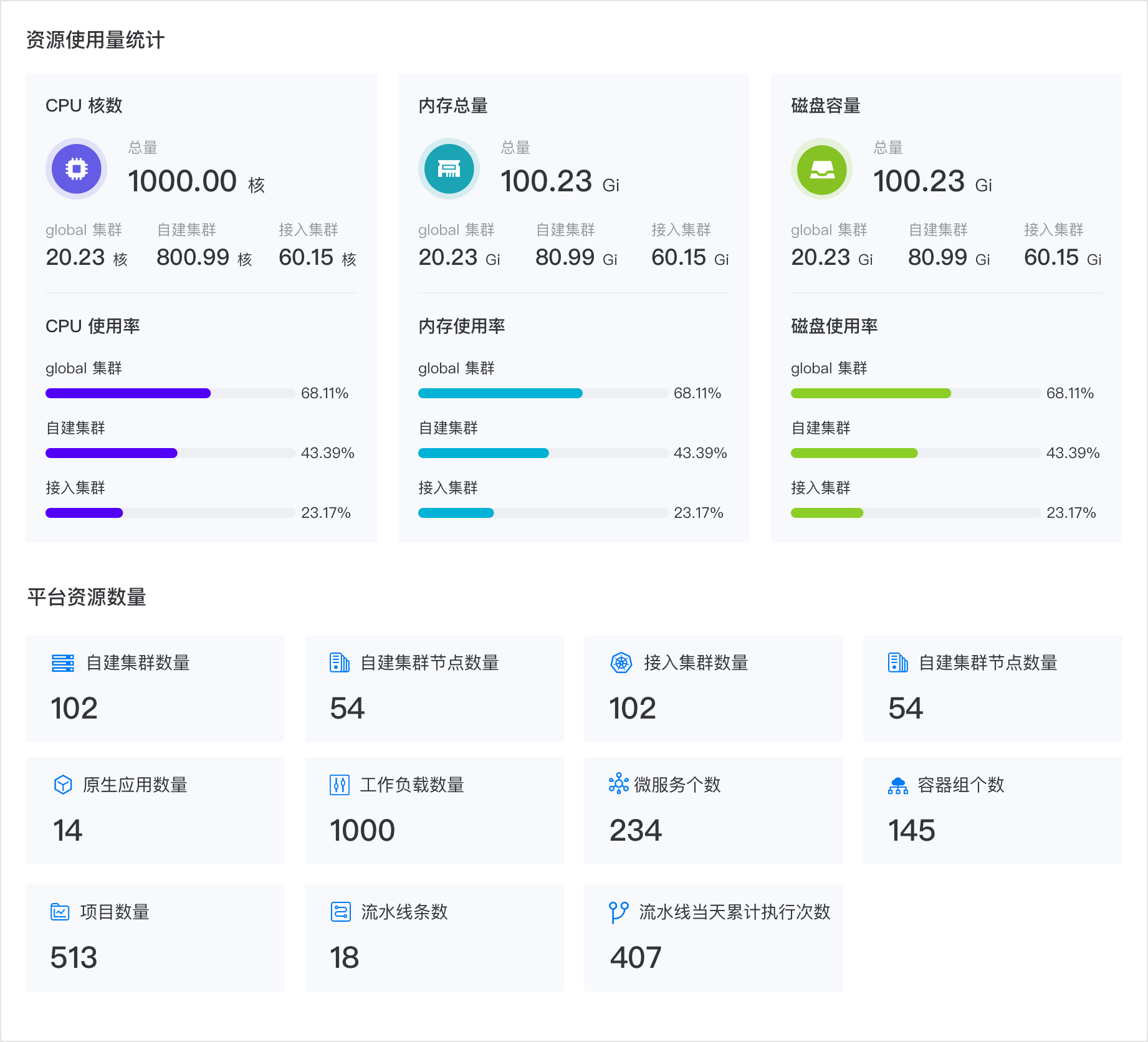
-
资源使用量统计:可查看 global 集群、接入集群和自建集群的 CPU、内存、磁盘总量和总使用率。
-
平台资源数量:可查看平台上正在运行的资源的个数。