集群监控
当平台上自建/接入的集群已部署了监控组件且监控组件运行正常时,支持通过可视化界面,查看集群的监控数据。
-
集群概览:查看集群的基本资源监控信息,包括:资源运行情况、资源使用情况、资源趋势统计数据、网络负载统计数据及网络健康状态。
-
查看组件监控数据:查看集群控制组件的监控信息,实时了解组件的运行情况和资源使用情况。
前提条件
-
集群状态正常。
-
集群已部署监控组件且监控组件运行正常。
监控数据操作说明
-
刷新控制:集群概览、监控页面的监控数据仅在页面打开时自动刷新一次,如需再次刷新监控数据,可通过以下两种方式实现:
-
手动刷新:通过单击页面右下角的
 手动刷新监控数据;
手动刷新监控数据; -
设置自动刷新(默认关闭):单击
 设置自动刷新监控数据的时间间隔。
设置自动刷新监控数据的时间间隔。
-
-
查看监控图表大图:单击图表右上角
 可在弹出的对话框中查看放大的,数据展示粒度细化后的监控图表。
可在弹出的对话框中查看放大的,数据展示粒度细化后的监控图表。 -
查看/设置图例:单击图表右上角
 可展开监控图表中的图例,单击图例,可隐藏/显示图表中图例对应的曲线。
可展开监控图表中的图例,单击图例,可隐藏/显示图表中图例对应的曲线。
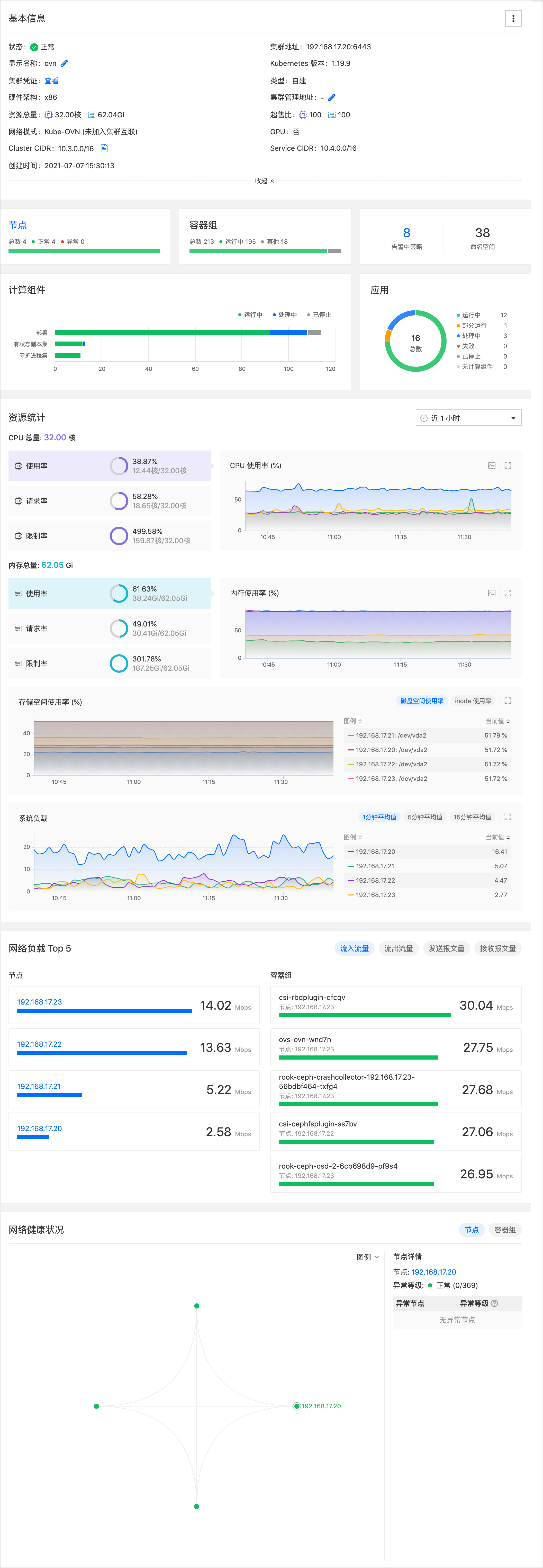
集群概览
-
在左侧导航栏中,单击 集群管理 > 集群。
-
单击待查看 集群名称。
在概览页面,可查看集群的基本信息、集群上资源的运行情况、资源的当前使用情况统计值以及对应的趋势统计图表。
提示:仅当自建集群为 GPU 集群时,会展示 GPU 相关监控数据;且仅当 GPU 资源类型为 vGPU 时,会展示显存监控数据。
资源统计数据说明如下:
-
单位:
-
1 颗 pGPU(物理 GPU)= 1 核 = 100 vGPU(虚拟 GPU)
-
1 单位显存 = 256 Mi
-
1024 Mi = 1 Gi
-
-
使用率 = 资源使用值 / 资源总额
-
请求率 = 资源请求值 / 资源总额
-
分配率 = 已分配资源值 / 资源总额
-
系统负载:1 分钟、5 分钟、15 分钟内的 CPU 平均负载。取值为当前正在被 CPU 执行和等待被 CPU 执行的进程数目总和与 CPU 最大能执行的进程数目的比值,是反映系统忙闲程度的重要指标。
-
查看组件监控数据
支持查看集群中核心 Kubernetes 组件的监控信息,帮助平台管理员或集群运维人员实时了解组件的运行情况和资源使用情况,避免因组件状态异常影响集群功能。
操作步骤
-
单击页面上方的 监控 页签,进入集群组件的监控信息页面。
提示:通过单击以组件名称命名的二级页签,可切换至对应组件的监控信息页面。
每个组件的监控信息主要由 监控概览、组件容器组列表、监控趋势统计 3 部分组成,如图所示(以 ApiServer 为例)。详细的监控信息说明参见 参考信息 。
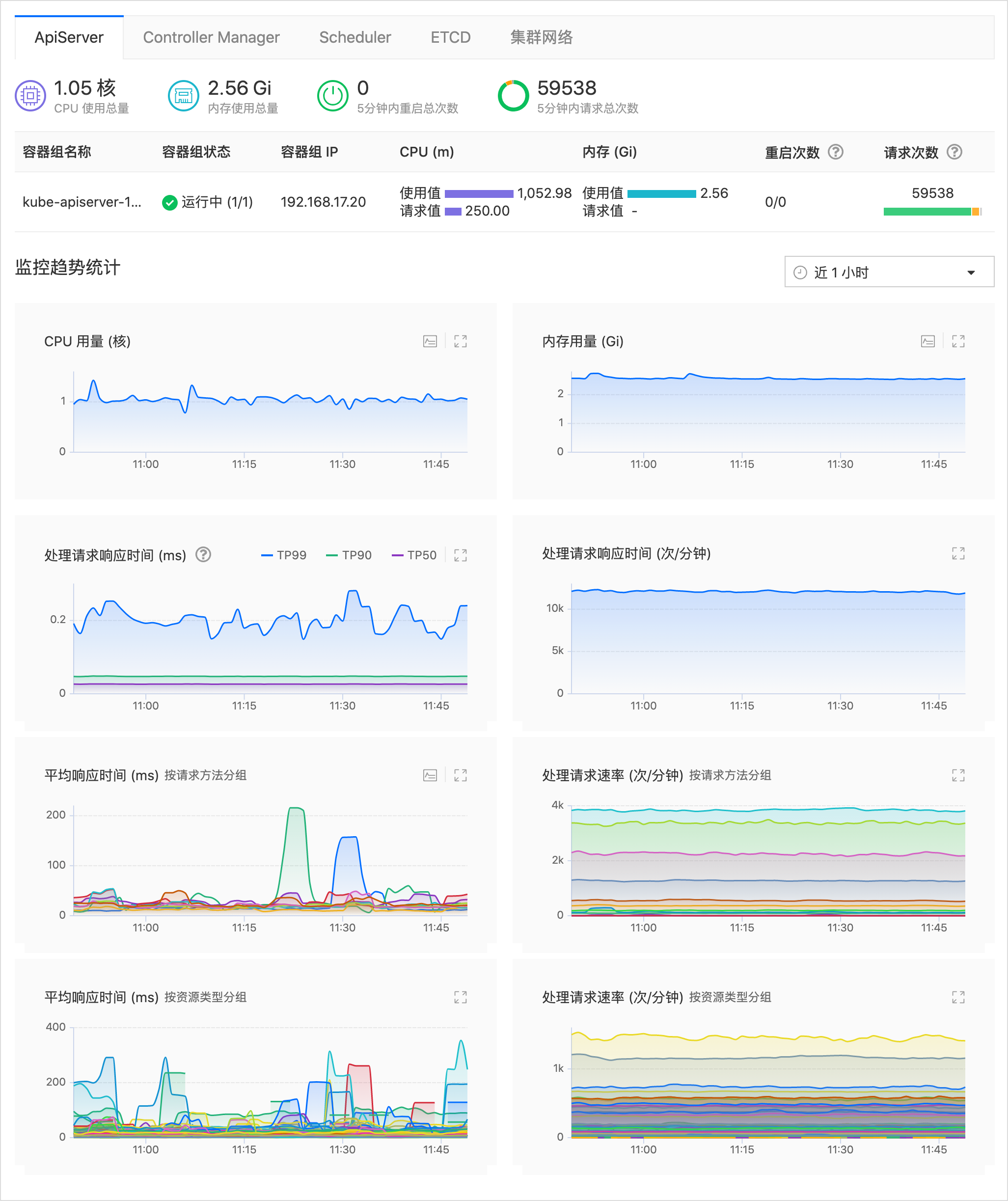
目前,支持查看监控概览和监控趋势统计数据的组件包括:
-
ApiServer :提供了 Kubernetes 各类资源对象的 POST、DELETE、PUT、GET 及 WATCH 等 HTTP Rest 接口,是整个系统的数据总线和数据中心。
-
Controller Manager :作为集群内部的管理控制中心,负责集群内的 Node、Pod 副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源配额(ResourceQuota)的管理,当某个 Node 意外宕机时,Controller Manager 会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。
-
Scheduler :运行在 master 节点,它的核心功能是监听 apiserver 来获取
PodSpec.NodeName为空的 Pod,通过为每个这样的 Pod 创建一个 binding 来指示 Pod 应该调度到哪个节点上。 -
ETCD :一个高可用的分布式
key-value存储系统,它提供了数据 TTL 失效、数据改变监视、多值、目录监听、分布式锁原子操作等功能,可用于服务发现、共享配置、管理集群节点的状态并保障节点数据的一致性。
-
参考信息
ApiServer
ApiServer 组件相关的监控信息字段说明参见以下表格。
表 ApiServer 监控概览
| 参数 | 说明 |
|---|---|
| CPU 使用总量 | 运行组件的容器组所用 CPU 的总量。 |
| 内存使用总量 | 运行组件的容器组所用内存的总量。 |
| 5 分钟内重启总次数 | 运行组件的容器组在最近的 5 分钟内重启的总次数。  :重启总数 = 0; :重启总数 = 0;  :1 =< 重启总数 <= 3; :1 =< 重启总数 <= 3; :重启总数 > 3。 :重启总数 > 3。 |
| 5 分钟内请求总数 | 运行组件的容器组在最近的 5 分钟内接收到的 HTTP 请求总数。 |
表 ApiServer 容器组列表
| 参数 | 说明 |
|---|---|
| 容器组名称 | 容器组的名称。 |
| 容器组状态 | 容器组的状态。 运行中:容器组中容器均处于正常运行状态。 处理中:容器组中有容器未处于运行中状态。 完成 :容器组已运行完成; 失败 :容器组有容器运行失败。 |
| 容器组 IP | 容器组的 IP 地址。 |
| CPU(核) | 容器组所用 CPU 的量(使用值)和对 CPU 的请求值(requests.cpu)。当节点上的可用资源小于容器组的请求值时,容器组无法正常启动。 |
| 内存(Gi) | 容器组所用内存的量(使用值)和对内存的请求值(requests.memory)。当节点上的可用资源小于容器组的请求值时,容器组无法正常启动。 |
| 重启次数 | 容器组在最近的 5 分钟内重启的次数和容器组自创建以来的总重启次数。 |
| 请求次数 | 容器组在最近的 5 分钟内接收到的 HTTP 请求个数。 |
表 ApiServer 监控趋势统计
| 参数 | 说明 |
|---|---|
| CPU 用量 | 指定时间范围内,运行组件的容器组的 CPU 使用量。 将光标移动至曲线图上时,将会显示指定时间点各容器组的 CPU 使用值。 |
| 内存用量 | 指定时间范围内,运行组件的容器组的内存使用量。 将光标移动至曲线图上时,将会显示指定时间点各容器组的内存使用值。 |
| 处理请求响应时间(ms) | 指定时间范围内,基于 TP99、TP90、TP50 性能指标统计的组件处理请求的平均响应时间。 TP99:满足 99% 的网络请求所需要的最低耗时; TP90:满足 90% 的网络请求所需要的最低耗时; TP50:满足 50% 的网络请求所需要的最低耗时。 |
| 处理请求速率(次/分钟) | 指定时间范围内,组件处理请求的平均速率。 按请求方法分组:按照请求的方法类型统计平均处理请求速率,每种方法一条曲线。例如:WATCH、CREATE、DELETE、GET、POST、PATCH、PUT、UPDATE、LIST; 按资源分组:统计所有资源的请求处理速率,每个资源一条曲线。。 |
| 平均响应时间(ms) | 指定时间范围内,组件处理请求的平均响应时间。 按请求方法分组:按照请求的方法类型统计平均响应时间,每类方法一条曲线。例如:WATCH、CREATE、DELETE、GET、POST、PATCH、PUT、UPDATE、LIST; 按资源类型分组:按照资源类型统计指定时间范围内的平均响应时间,每类资源一条曲线。 |
Controller Manager
Controller Manager 组件相关的监控信息字段说明参见以下表格。
表 Controller Manager 监控概览
| 参数 | 说明 |
|---|---|
| CPU 使用总量 | 运行组件的容器组所用 CPU 的总量。 |
| 内存使用总量 | 运行组件的容器组所用内存的总量。 |
| 5 分钟内重启总次数 | 运行组件的容器组在最近的 5 分钟内重启的总次数。 :重启总数 = 0; :1 =< 重启总数 <= 3; :重启总数 > 3。 |
表 Controller Manager 容器组列表
| 参数 | 说明 |
|---|---|
| 容器组名称 | 容器组的名称。 |
| 容器组状态 | 容器组的状态。 运行中:容器组中容器均处于正常运行状态。 处理中:容器组中有容器未处于运行中状态。 完成 :容器组已运行完成; 失败 :容器组有容器运行失败。 |
| 容器组 IP | 容器组的 IP 地址。 |
| CPU(核) | 容器组所用 CPU 的量(使用值)和对 CPU 的请求值(requests.cpu)。当节点上的可用资源小于容器组的请求值时,容器组无法正常启动。 |
| 内存(Gi) | 容器组所用内存的量(使用值)和对内存的请求值(requests.memory)。当节点上的可用资源小于容器组的请求值时,容器组无法正常启动。 |
| 重启次数 | 容器组在最近的 5 分钟内重启的次数和容器组自创建以来的总重启次数。 |
表 Controller Manager 监控趋势统计
| 参数 | 说明 |
|---|---|
| CPU 用量 | 指定时间范围内,运行组件的容器组的 CPU 使用量。 将光标移动至曲线图上时,将会显示指定时间点各容器组的 CPU 使用值。 |
| 内存用量 | 指定时间范围内,运行组件的容器组的内存使用量。 将光标移动至曲线图上时,将会显示指定时间点各容器组的内存使用值。 |
| 排队平均延迟 (ms) | 指定时间范围内,队列中排队的资源在等待被处理前的平均延迟时间。 将光标移动至曲线图上时,将会显示指定时间点,前 15 个资源的平均延迟时间,图例会按照延迟时间倒序排列;当资源不足 15 个时,仅显示有统计数据的资源。 |
| 处理平均延迟 (ms) | 指定时间范围内,资源在被处理前的平均延迟时间。 将光标移动至曲线图上时,将会显示指定时间点,前 15 个资源的平均延迟时间,图例会按照延迟时间倒序排列;当资源不足 15 个时,仅显示有统计数据的资源。 |
| 资源添加速率(次/分钟) | 指定时间范围内,资源被添加的速率。 |
| 队列深度 (个) | 指定时间范围内,在端口队列中等待服务的 I/O 请求数量。 |
Scheduler
Scheduler 组件相关的监控信息字段说明参见以下表格。
表 Scheduler 监控概览
| 参数 | 说明 |
|---|---|
| CPU 使用总量 | 运行组件的容器组所用 CPU 的总量。 |
| 内存使用总量 | 运行组件的容器组所用内存的总量。 |
| 5 分钟内重启总次数 | 运行组件的容器组在最近的 5 分钟内重启的总次数。 :重启总数 = 0; :1 =< 重启总数 <= 3; :重启总数 > 3。 |
| 5 分钟内调度总次数 | 组件在最近的 5 分钟内的实现调度的总数。 |
表 Scheduler 容器组列表
| 参数 | 说明 |
|---|---|
| 容器组名称 | 容器组的名称。 |
| 容器组状态 | 容器组的状态。 运行中:容器组中容器均处于正常运行状态。 处理中:容器组中有容器未处于运行中状态。 完成 :容器组已运行完成; 失败 :容器组有容器运行失败。 |
| 容器组 IP | 容器组的 IP 地址。 |
| CPU(核) | 容器组所用 CPU 的量(使用值)和对 CPU 的请求值(requests.cpu)。当节点上的可用资源小于容器组的请求值时,容器组无法正常启动。 |
| 内存(Gi) | 容器组所用内存的量(使用值)和对内存的请求值(requests.memory)。当节点上的可用资源小于容器组的请求值时,容器组无法正常启动。 |
| 重启次数 | 容器组在最近的 5 分钟内重启的次数和容器组自创建以来的总重启次数。 |
| 调度次数 | 容器组在最近的 5 分钟内实现调度的次数。 |
表 Scheduler 监控趋势统计
| 参数 | 说明 |
|---|---|
| CPU 用量 | 指定时间范围内,运行组件的容器组的 CPU 使用量。 将光标移动至曲线图上时,将会显示指定时间点各容器组的 CPU 使用值。 |
| 内存用量 | 指定时间范围内,运行组件的容器组的内存使用量。 将光标移动至曲线图上时,将会显示指定时间点各容器组的内存使用值。 |
| 调度延迟(ms) | 指定时间范围内,队列中排队的 Pod 在等待被调度前的平均延迟时间,基于 TP99、TP90、TP50 性能指标统计。 将光标移动至曲线图上时,将会显示指定时间点前 5 分钟的延迟时间的 TP99、TP90、TP50 数据。 TP99:满足 99% 的网络请求所需要的最低耗时; TP90:满足 90% 的网络请求所需要的最低耗时; TP50:满足 50% 的网络请求所需要的最低耗时。 |
| 调度速率(次/分钟) | 指定时间范围内,调度成功的和调度失败的次数统计曲线。 将光标移动至曲线图上时,将会显示指定时间点前 1 分钟的调度成功总数和调度失败总数。 |
ETCD
ETCD 组件相关的监控信息字段说明参见以下表格。
表 ETCD 监控概览
| 参数 | 说明 |
|---|---|
| CPU 使用总量 | 运行组件的容器组所用 CPU 的总量。 |
| 内存使用总量 | 运行组件的容器组所用内存的总量。 |
| 5 分钟内重启总次数 | 运行组件的容器组在最近的 5 分钟内重启的总次数。 :重启总数 = 0; :1 =< 重启总数 <= 3; :重启总数 > 3。 |
| 近 1 天内 Leader 变更总次数 | 运行组件的容器组在最近的 1 天内,Leader 发生变更的总次数。 说明: 频繁更换 Leader 将显著影响 ETCD 的性能。 Leader 不稳定,可能是由于网络连接问题或 ETCD 集群负载过高所致。 |
表 ETCD 容器组列表
| 参数 | 说明 |
|---|---|
| 容器组名称 | 容器组的名称。 |
| 容器组状态 | 容器组的状态。 运行中:容器组中容器均处于正常运行状态。 处理中:容器组中有容器未处于运行中状态。 完成 :容器组已运行完成; 失败 :容器组有容器运行失败。 |
| 容器组 IP | 容器组的 IP 地址。 |
| ETCD 状态 | ETCD 容器组所在节点的状态。 Leader:容器组所在节点为 Leader,Leader 是由 Raft 共识协议选举出来的,没有 Leader,集群将不允许任何的数据更新操作。选举完成以后,集群会通过心跳的方式维持 Leader 的地位,一旦 Leader 失效,会有新的 Follower 来竞选 Leader; Follower:Leader 选举没有成功的节点即为 Follower。 |
| CPU(核) | 容器组所用 CPU 的量(使用值)和对 CPU 的请求值(requests.cpu)。当节点上的可用资源小于容器组的请求值时,容器组无法正常启动。 |
| 内存(Gi) | 容器组所用内存的量(使用值)和对内存的请求值(requests.memory)。当节点上的可用资源小于容器组的请求值时,容器组无法正常启动。 |
| 重启次数 | 容器组在最近的 5 分钟内重启的次数和容器组自创建以来的总重启次数。 |
表 ETCD 监控趋势统计
| 参数 | 说明 |
|---|---|
| CPU 用量 | 指定时间范围内,运行组件的容器组的 CPU 使用量。 将光标移动至曲线图上时,将会显示指定时间点各容器组的 CPU 使用值。 |
| 内存用量 | 指定时间范围内,运行组件的容器组的内存使用量。 将光标移动至曲线图上时,将会显示指定时间点各容器组的内存使用值。 |
| 数据库大小 | 指定时间范围内,容器组的数据库大小。 将光标移动至曲线图上时,将会显示指定时间点各容器组的库大小,例如:192.168.16.53:2379 库大小 88.88 Mi。 |
| 资源数量 | 指定时间范围内,根据类型统计的 Top 10 的资源数量。 将光标移动至曲线图上时,将会显示指定时间点,前 15 个类型资源的数量;当资源类型不足 15 个时,仅显示有统计数据的资源。 |
| 客户端网络流量接收速率 | 指定时间范围内,每个容器组的网络流量接收速率。 将光标移动至曲线图上时,将会显示各容器组指定时间点前 5 分钟的平均网络流量接收速率。 |
| 客户端网络流量发送速率 | 指定时间范围内,每个容器组的网络流量发送速率。 将光标移动至曲线图上时,将会显示各容器组指定时间点前 5 分钟的平均网络流量发送速率。 |
| WAL 同步时间 | 指定时间范围内,每个容器组的 WAL(Write-ahead logging,预写日志)调用 fsync 的延迟。当 ETCD 在应用日志条目并将日志条目持久保存到磁盘时,将调用 wal_fsync。将光标移动至曲线图上时,将会显示指定时间点前 5 分钟的同步时间的 TP99、TP90、TP50 数据。 TP99:满足 99% 的网络请求所需要的最低耗时; TP90:满足 90% 的网络请求所需要的最低耗时; TP50:满足 50% 的网络请求所需要的最低耗时。 |
| 库同步时间 | 指定时间范围内,后端调用的提交延迟分布。 当 ETCD 将其最新的增量快照提交到磁盘时,将调用 backend_commit。 需要注意的是,磁盘操作延迟较大(WAL 日志同步时间较长或库同步时间较长)通常表示磁盘有问题,这可能会导致请求延迟过高或集群不稳定。将光标移动至曲线图上时,将会显示指定时间点前 5 分钟的同步时间的 TP99、TP90、TP50 数据。 TP99:满足 99% 的网络请求所需要的最低耗时; TP90:满足 90% 的网络请求所需要的最低耗时; TP50:满足 50% 的网络请求所需要的最低耗时。 |
| RPC 速率 | 指定时间范围内,服务端的 RPC 流消息收发成功、失败的速率。 将光标移动至曲线图上时,将会显示指定时间点成功、失败的速率。 |
| Raft 提议速率 | 指定时间范围内,Raft 提议的提交速率。记录提交的协商一致提议的速率。如果群集运行状况良好,则此指标应随着时间的推移而增加。 将光标移动至曲线图上时,将会显示指定时间点前 1 分钟的提交、排队、应用、失败速率。 |