为自建的业务集群配置 GPU 节点
随着业务数据量的增加,尤其对于人工智能、数据分析等场景,您可能希望在自建的业务集中使用 GPU 功能以加速数据处理。对此,除了为集群节点准备 GPU 资源外,还应对其进行 GPU 配置。
本方案将集群中具备 GPU 计算能力的节点称为 GPU 节点。可以是安装了 GPU 显卡的物理机节点(pGPU),也可以是使用 GPU 虚拟化能力的虚拟机节点(vGPU)。
说明:若无特指,操作步骤将同时适用于两类节点。驱动安装相关问题可参考 NVIDIA 官网安装文档 。
适用场景
-
如果您正准备创建集群,且已备有 GPU 节点,仅需分别为 GPU 节点 安装 GPU 驱动 ,然后可完成集群创建。集群创建过程中,平台将自动完成后续配置。
-
如果是已有集群,且创建集群时未准备 GPU 资源,集群创建完毕后希望在已有节点或新加入的节点上使用 GPU 能力,请完整执行本节所有操作。
前提条件
操作节点上已准备好 GPU 资源,即属于本节所说的 GPU 节点。
操作系统支持情况
| 操作系统 | 运行时组件 | 创建集群 | 已有非 GPU 集群 |
| CentOS 7.9 | Containerd | ||
| Docker |
安装 GPU 驱动
获取驱动下载地址
-
登录 GPU 节点,执行命令
lspci |grep -i NVIDIA查看节点的 GPU 型号。以下示例中 GPU 型号为:Tesla T4。
lspci | grep NVIDIA 00:08.0 3D controller: NVIDIA Corporation TU104GL [Tesla T4] (rev a1) -
前往 NVIDIA 官网 ,获取驱动下载地址。
-
在官网首页的顶部导航栏中,单击 驱动程序。
-
根据 GPU 节点的型号,填写驱动下载所需信息,如下图所示。

-
单击 搜索。
-
单击 下载。
-
右键单击 下载 > 复制链接地址,即可复制驱动的下载地址。
-
-
在 GPU 节点上依次执行以下命令行,创建
/home/gpu目录,并将驱动文件下载并保存至该目录下。# 创建 /home/gpu 目录 mkdir -p /home/gpu cd /home/gpu/ # 将驱动文件下载至 /home/gpu 目录下,示例:wget https://cn.download.nvidia.com/tesla/515.65.01/NVIDIA-Linux-x86_64-515.65.01.run wget <驱动下载地址> # 验证驱动文件是否下载成功,若返回驱动文件名称(例如:NVIDIA-Linux-x86_64-515.65.01.run)表明已下载成功 ls <驱动文件名称>
安装驱动
-
在 GPU 节点上执行以下命令行,安装当前操作系统对应的 gcc 和 kernel-devel 包。
sudo yum install dkms gcc kernel-devel-$(uname -r) -y -
依次执行以下命令,安装 GPU 驱动。
chmod a+x /home/gpu/<驱动文件名称> /home/gpu/<驱动文件名称> --dkms -
安装完成后,执行
nvidia-smi命令,若返回类似以下示例的 GPU 信息,说明驱动安装成功。# nvidia-smi Tue Sep 13 01:31:33 2022 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 515.65.01 Driver Version: 515.65.01 CUDA Version: 11.7 | +-------------------------------+-----------------------+---------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 Off | 00000000:00:08.0 Off | 0 | | N/A 55C P0 28W / 70W | 2MiB / 15360MiB | 5% Default | | | | N/A | +-------------------------------+-----------------------+---------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+
(仅虚拟 GPU)修改配置
确保即使重启虚拟 GPU 节点也可以正确加载相关模块。
说明:对于新集群,结束前述步骤结束后您已经可以创建集群。待将虚拟 GPU 节点加入集群后,再参考以下步骤修改虚拟 GPU 节点配置。
-
修改文件
/etc/systemd/system/kubelet.service。vi /etc/systemd/system/kubelet.service -
在文件的
Unit配置项中添加参数。[Unit] Description=kubelet: The Kubernetes Node Agent Documentation=https://kubernetes.io/docs/[Service] User=root ExecStart=/usr/bin/kubelet # 增加如下内容 ExecStartPre=/bin/bash -c 'modprobe nvidia-uvm;nvidia-modprobe -u -c=0' Restart=always StartLimitInterval=0 RestartSec=10 -
重启服务。
systemctl daemon-reload systemctl restart kubelet -
执行命令。
modprobe nvidia-uvm;nvidia-modprobe -u -c=0
物理 GPU 配置
配置 NVIDIA 容器运行时
-
在 GPU 节点上,添加 NVIDIA yum 源。
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) && curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.repo | sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo yum makecache -y提示
Metadata cache created.时,表示添加成功。 -
安装 NVIDIA 容器运行时。
yum install nvidia-container-toolkit -y提示
Complete!时,表示安装成功。 -
在文件中添加以下配置。
-
Containerd:修改
/etc/containerd/config.toml文件。[plugins] [plugins."io.containerd.grpc.v1.cri"] [plugins."io.containerd.grpc.v1.cri".containerd] ... default_runtime_name = "nvidia" ... [plugins."io.containerd.grpc.v1.cri".containerd.runtimes] ... [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc] runtime_type = "io.containerd.runc.v2" runtime_engine = "" runtime_root = "" privileged_without_host_devices = false base_runtime_spec = "" [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options] SystemdCgroup = true [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia] privileged_without_host_devices = false runtime_engine = "" runtime_root = "" runtime_type = "io.containerd.runc.v1" [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options] BinaryName = "/usr/bin/nvidia-container-runtime" SystemdCgroup = true ... -
Docker:修改
/etc/docker/daemon.json文件。{ ... "default-runtime": "nvidia", "runtimes": { "nvidia": { "path": "/usr/bin/nvidia-container-runtime" } }, ... }
-
-
重启 Containerd / Docker。
-
Containerd
systemctl restart containerd #重启 crictl info |grep Runtime #检查 -
Docker
systemctl restart docker #重启 docker info |grep Runtime #检查
-
部署 nvidia-device-plugin
-
为 GPU 节点增加 Label,请修改
gpuNodes为 GPU 节点名称,并执行以下命令:kubectl label node <gpuNodes> nvidia-device-enable=enable --overwrite -
在 global 集群获取 nvidia-device-plugin 版本信息,执行命令:
kubectl get prdb base -o yaml | grep acp/chart-nvidia-device-plugin -A 1获取输出的
version字段值,输出示例:- name: acp/chart-nvidia-device-plugin version: v3.9.0-alpha.8 -
在 global 集群获取私有镜像仓库地址,执行命令:
kubectl get prdb base -o=jsonpath='{.spec.registry.address}'获取输出的地址信息,输出示例:
192.168.130.240:11443 -
使用 Sentry 在业务集群控制节点部署 nvidia-device-plugin,使用获取到的私有镜像仓库地址和 nvidia-device-plugin 版本,分别修改下面示例中
export命令中的REGISTRY_ADDRESS、PGPU_VERSION字段值后,将全部内容粘贴至命令行中执行:export REGISTRY_ADDRESS="192.168.130.240:11443" export PGPU_VERSION="v3.9.0-alpha.8" cat << EOF |kubectl apply -f - apiVersion: operator.alauda.io/v1alpha1 kind: AppRelease metadata: name: pgpu namespace: cpaas-system finalizers: - finalizers.apprelease spec: source: charts: - name: acp/chart-nvidia-device-plugin releaseName: pgpu targetRevision: ${PGPU_VERSION} repoURL: ${REGISTRY_ADDRESS} values: global: registry: address: ${REGISTRY_ADDRESS} EOF -
检查
nvidia-device-plugin-daemonsetPod 状态,确保为Running状态。kubectl -n kube-system get pods |grep nvidia nvidia-device-plugin-daemonset-9ebhj 1/1 Running 0 45m
修改业务集群配置
在 global 集群的控制节点 上,执行以下命令:
kubectl patch cluster {业务集群名称} -p '{"spec":{"features":{"gpuType": "Physical"}}}'虚拟 GPU 配置
配置 kube-scheduler (kubernetes < 1.23)
-
在 业务集群控制节点 上,检查调度器(Scheduler)中是否正确引用调度策略。
cat /etc/kubernetes/manifests/kube-scheduler.yaml检查项 期望结果 参数 -policy-config-file 值 /etc/kubernetes/scheduler-policy-config.json (即调度策略文件) 说明:上述参数和值为平台默认配置,如果您已自行修改,请将其改回默认值。原自定义配置可复制到调度策略文件中。
-
检查调度策略文件配置。
-
执行命令:
kubectl describe service kubernetes -n default |grep Endpoints。期望效果Endpoints: 192.168.130.240:6443 -
将所有 Master 节点的
/etc/kubernetes/scheduler-policy-config.json这个文件内容替换成如下内容,其中${apiserver}改为第一步的输出结果。{ "apiVersion" : "v1", "extenders" : [ { "apiVersion" : "v1beta1", "filterVerb" : "predicates", "managedResources" : [ { "ignoredByScheduler" : false, "name" : "tencent.com/vcuda-core" } ], "nodeCacheCapable" : false, "urlPrefix" : "https://${apiserver}/api/v1/namespaces/kube-system/services/gpu-quota-admission/proxy/scheduler", "enableHttps": true, "tlsConfig":{ "insecure": false, "certFile": "/etc/kubernetes/pki/apiserver-kubelet-client.crt", "keyFile": "/etc/kubernetes/pki/apiserver-kubelet-client.key", "caFile": "/etc/kubernetes/pki/ca.crt" } } ], "kind" : "Policy" }
-
-
执行以下命令获取容器 ID:
-
Containerd:执行
crictl ps |grep kube-scheduler,输出结果如下,第一列为容器 ID。1d113ccf1c1a9 03c72176d0f15 2 seconds ago Running kube-scheduler 3 ecd054bbdd465 kube-scheduler-192.168.176.47 -
Docker:执行
docker ps |grep kube-scheduler,输出结果如下,第一列为容器 ID。30528a45a118 d8a9fef7349c "kube-scheduler --au…" 37 minutes ago Up 37 minutes k8s_kube-scheduler_kube-scheduler-192.168.130.240_kube-system_3e9f7007b38f4deb6ffd1c7587621009_28
-
-
使用上一步获取到的容器 ID 重启 Containerd/Docker 容器。
-
Containerd
crictl stop <容器 ID> -
Docker
docker stop <容器 ID>
-
-
重启 Kubelet。
systemctl restart kubelet
配置 kube-scheduler (kubernetes >= 1.23)
-
在 业务集群控制节点 上,检查调度器(Scheduler)中是否正确引用调度策略。
cat /etc/kubernetes/manifests/kube-scheduler.yaml检查项 期望结果 参数 –config 值 /etc/kubernetes/scheduler-config.yaml (即调度策略文件) 说明:上述参数和值为平台默认配置,如果您已自行修改,请将其改回默认值。原自定义配置可复制到调度策略文件中。
-
检查调度策略文件配置。
-
执行命令:
kubectl describe service kubernetes -n default |grep Endpoints。期望效果Endpoints: 192.168.130.240:6443 -
将所有 Master 节点的
/etc/kubernetes/scheduler-config.yaml这个文件内容替换成如下内容,其中${kube-apiserver}改为第一步的输出结果。apiVersion: kubescheduler.config.k8s.io/v1beta2 kind: KubeSchedulerConfiguration clientConnection: kubeconfig: /etc/kubernetes/scheduler.conf extenders: - enableHTTPS: true filterVerb: predicates managedResources: - ignoredByScheduler: false name: tencent.com/vcuda-core nodeCacheCapable: false urlPrefix: https://${kube-apiserver}/api/v1/namespaces/kube-system/services/gpu-quota-admission/proxy/scheduler tlsConfig: insecure: false certFile: /etc/kubernetes/pki/apiserver-kubelet-client.crt keyFile: /etc/kubernetes/pki/apiserver-kubelet-client.key caFile: /etc/kubernetes/pki/ca.crt
-
-
执行以下命令获取容器 ID:
-
Containerd:执行
crictl ps |grep kube-scheduler,输出结果如下,第一列为容器 ID。1d113ccf1c1a9 03c72176d0f15 2 seconds ago Running kube-scheduler 3 ecd054bbdd465 kube-scheduler-192.168.176.47 -
Docker:执行
docker ps |grep kube-scheduler,输出结果如下,第一列为容器 ID。30528a45a118 d8a9fef7349c "kube-scheduler --au…" 37 minutes ago Up 37 minutes k8s_kube-scheduler_kube-scheduler-192.168.130.240_kube-system_3e9f7007b38f4deb6ffd1c7587621009_28
-
-
使用上一步获取到的容器 ID 重启 Containerd/Docker 容器。
-
Containerd
crictl stop <容器 ID> -
Docker
docker stop <容器 ID>
-
-
重启 Kubelet。
systemctl restart kubelet
部署 gpu-manager
-
为 GPU 节点增加 Label,请修改
gpuNodes为 GPU 节点名称,并执行以下命令:kubectl label node <gpuNodes> nvidia-device-enable=enable --overwrite -
在 global 集群获取 gpu-manager 版本信息,执行命令:
kubectl get prdb base -o yaml | grep acp/chart-gpu-manager -A 1获取输出的
version字段值,输出示例:- name: acp/chart-gpu-manager version: v3.9.0-alpha.26 -
在 global 集群获取私有镜像仓库地址,执行命令:
kubectl get prdb base -o=jsonpath='{.spec.registry.address}'获取输出的地址信息,输出示例:
192.168.130.240:11443 -
使用 Sentry 在业务集群控制节点部署 gpu-manager,使用获取到的私有镜像仓库地址和 gpu-manager 版本,分别修改下面示例中
export命令中的REGISTRY_ADDRESS、PGPU_VERSION字段值后,将全部内容粘贴至命令行中执行:export REGISTRY_ADDRESS="192.168.130.240:11443" export GPU_MANAGER_VERSION=v3.9.0-alpha.26 cat << EOF |kubectl apply -f - apiVersion: operator.alauda.io/v1alpha1 kind: AppRelease metadata: name: vgpu namespace: cpaas-system finalizers: - finalizers.apprelease spec: source: charts: - name: acp/chart-gpu-manager releaseName: vgpu targetRevision: ${GPU_MANAGER_VERSION} repoURL: ${REGISTRY_ADDRESS} values: global: registry: address: ${REGISTRY_ADDRESS} EOF -
检查 gpu-manager-daemonset 运行情况,执行以下命令:
kubectl get pods -n kube-system |grep gpu确保所有容器为
Running状态,效果如下:gpu-manager-daemonset-s5kch 1/1 Running 1 1h gpu-quota-admission-776b559bdd-q59nd 1/1 Running 1 1h
修改业务集群配置
在 global 集群的控制节点 上,执行以下操作。
kubectl patch cluster {业务集群名称} -p '{"spec":{"features":{"gpuType": "Virtual"}}}'结果验证
方式一:在业务集群的控制节点检查 GPU 节点上是否有可分配的 GPU 资源,执行以下命令:
kubectl get node ${nodeName} -o=jsonpath='{.status.allocatable}' 方式二:部署一个 GPU 应用,检查是否有 GPU 相关的资源消耗,业务集群的 GPU 节点执行以下命令:
nvidia-smi pmon -s u -d 1查得 sm 和 mem 均有数据时,说明 GPU 功能已就绪。您可在 GPU 节点上开始 GPU 应用开发。
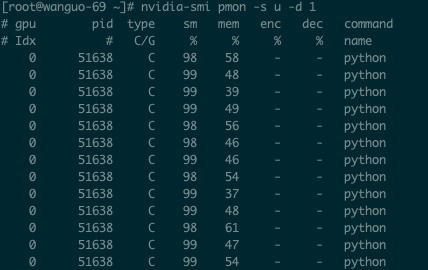
注意:部署 GPU 应用时,务必要配置以下必填参数。
物理 GPU
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpu-test-nvidia
spec:
spec:
containers:
- image: <GPU 镜像>
imagePullPolicy: IfNotPresent
name: gpu
resources:
limits:
cpu: '2'
memory: 4Gi
nvidia.com/gpu: 1 # 必填虚拟 GPU
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpu-test-nvidia
spec:
spec:
containers:
- image: <GPU 镜像>
imagePullPolicy: IfNotPresent
name: gpu
resources:
limits:
cpu: '2'
memory: 4Gi
tencent.com/vcuda-core: '20' # 必填
tencent.com/vcuda-memory: '20' # 必填后续操作
操作完毕后,如需添加其他 GPU 节点,在 为自建集群添加节点 时勾选该节点的 GPU 选项即可。